





1. Introduction▲
Zip avec les sources utilisées pour cet article : tuto-csv.zip.
Les fichiers CSV sont des fichiers (texte) dans lesquels on écrit des données organisées par ligne. Ce type de fichier est très utilisé pour envoyer des données (par FTP, par email, etc.). Par exemple les résultats des tirages du loto (ordre des boules, gains, etc.) sont disponibles au téléchargement sous forme de fichier CSV sur le site de la Française des Jeux.
Les fichiers CSV (pour « Comma Separated Values ») sont légers et réellement simples à manipuler. La lecture d'un fichier CSV en Java nécessite néanmoins l'utilisation d'un certain nombre de classes et de concepts qui, bien que basiques, ne sont pas si évidents à maîtriser, en particulier lorsqu'ils sont mis bout à bout.
Quand j'explique la lecture d'un CSV à mes élèves, je vois comme de la souffrance dans leurs regards ; le puzzle est difficile à assembler. Quand c'est avec des collègues que j'aborde le même sujet, il a d'abord l'air parfaitement connu, mais plus les minutes passent et plus les concepts mis en œuvre semblent resurgir d'un passé lointain. Dans les deux cas, les questions affluent rapidement.
Cet article traite donc des manipulations sur les fichiers CSV en Java. Dans une première partie, après une présentation rapide du format CSV, je montrerai comment lire un fichier CSV de manière simplifiée, pas à pas, puis je compléterai progressivement les exemples pour aborder des points/fonctionnalités de plus en plus complexes (titres, maps, séparateurs, optimisation, synchro, autoreload, écriture, etc.)
Pour des raisons didactiques évidentes, les algorithmes utilisés sont volontairement naïfs. Un chapitre est donc spécialement dédié aux optimisations.
Les codes proposés dans cet article peuvent être tronqués et/ou incomplets pour simplifier la lecture. C'est notamment le cas des try/catch et des tests unitaires. Les sources complètes sont disponibles dans le Zip en téléchargement.
1-A. À propos de ce document▲
En préparant cet article, j'ai fait un petit tour sur le Net, où j'ai trouvé de nombreuses librairies et encore plus de forums qui donnent des solutions aux questions classiques quand on travaille avec les CSV.
Or la lecture des fichiers CSV nécessite la maîtrise de compétences importantes. Il est vrai que l'existence de framework dispense d'avoir à traiter ces points, mais il me semble indispensable de les aborder au moins une fois, pour comprendre de quoi il retourne vraiment, même approximativement. Cela me semble d'ailleurs d'autant plus important que cet article a initialement été pensé pour mes élèves.
Ce document a été écrit de telle sorte que chaque nouveau chapitre complète le précédent. C'est pourquoi certains blocs de code ne sont clairement pas programmés de manière « propre » et qu'il y a notamment des copiés-collés un peu partout. Dans un vrai programme, il faudrait faire un peu de ménage. D'ailleurs, le code présent dans le Zip et en annexes n'est pas tout à fait le même.
1-B. À propos du code▲
J'ai fait le choix du franglais (mélange de français et d'anglais) pour écrire les codes proposés dans cet article. J'utilise le français quand je parle des chiens (cf. plus bas) et l'anglais quand je traite de points techniques et/ou conventionnels (ex. getters, singleton, etc.) Ce choix est parfois effectué dans des vrais projets d'entreprise.
Bien que ce ne soit pas la voie suivie par Sun (dans le JDK), de nombreuses équipes utilisent des conventions de nommage pour distinguer rapidement les interfaces et les classes. Par exemple, en préfixant les interfaces par « I » ou en suffixant les classes par « Impl » (pour implémentation). Dans le cadre des chiens (cf. plus bas), cela donnerait donc « IChien » pour l'interface décrivant un chien et « ChienImpl » pour son implémentation. Cette pratique a l'air triviale, mais elle apporte une vraie clarté dans les programmes. La société Sun, quant à elle, aurait nommé ces mêmes objets « Chien » et « DefaultChien » (ou « SimpleChien » selon les cas). Bien qu'un peu moins clair, c'est ce dernier type de nommage qui est utilisé dans cet article.
Enfin je souhaite insister sur le fait que les codes et/ou algorithmes présentés dans cet article ont été pensés et écrits dans un but pédagogique. Ils ne traitent pas de certaines problématiques, comme la volumétrie des données (il existe des applications qui utilisent des fichiers CSV pesant plusieurs Go) ou comme la charge mémoire. Ces algorithmes ne sont donc pas destinés à une utilisation professionnelle.
1-C. À propos des tests▲
Les morceaux de code proposés dans cet article ont été écrits et testés dans Eclipse. J'ai créé le projet Eclipse et ajouté les dépendances nécessaires à l'aide de Maven. Pour les tests, j'utilise le framework JUnit qui fait référence. On peut trouver une bonne présentation de JUnit sur developpez.com<point>
1-D. Mises à jour▲
1er mars 2014 : ajout du chapitre « Trois ans plus tard » dans lequel j'explique qu'il est efficace de traiter les lignes d'un fichier CSV par petits lots, lorsque c'est possible, et que c'est le sens de l'histoire.
2. Format CSV▲
Le format des fichiers CSV (Comma Separated Values) est l'un des plus simples qu'on puisse imaginer. Les données sont organisées par ligne. Une ligne peut contenir plusieurs champs/colonnes séparés par des virgules. La première ligne donne (souvent) les titres des colonnes. Bien entendu, l'ordre des colonnes est le même dans toutes les lignes.
Id,Prénom,Couleur,Age
1,Titi,Jaune,5
2,Médor,Noir,10
3,Pitié,Noir,5
4,Juju,Gris,5
5,Vanille,Blanc,7
6,Chocolat,Marron,12
7,Milou,Blanc,3
8,Idefix,Blanc,14
9,Pluto,Jaune,17
10,Dingo,Roux,1Comme le montre cet exemple, les fichiers CSV sont très concis et très peu verbeux (contrairement au format XML par exemple).
Le format CSV est défini par la RFC 4180RFC 4180 : « Common Format and MIME Type for Comma-Separated Values (CSV) Files. »
Certains éléments de cet article ne font pas partie de la RFC 4180. C'est par exemple le cas des lignes vides ou des lignes de commentaire (cf. chapitre V.Ligne de titre) qui sont néanmoins très souvent utilisées dans les « vraies » applications. En plus de la RFC 4180, il existe donc tout un ensemble de règles plus ou moins admises et qui sont présentées ici.
2-A. Pour la consultation▲
On voit d'un seul coup d'œil la structure des données d'un fichier CSV. Si en plus, on utilise une tabulation comme séparateur de colonne à la place de la virgule, la structure devient encore plus claire. Le changement de séparateur est abordé au chapitre « VII. Les autres séparateurs »
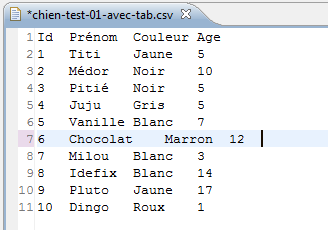
On constate, sur cet exemple, que la tabulation apporte un gain de lisibilité au lecteur, même s'il n'y a aucune différence du point de vue de l'ordinateur. Globalement la structure est claire et une seule ligne (Chocolat) possède une mise en forme légèrement décalée.
Pour avoir une vision encore plus claire d'un fichier CSV, on peut l'ouvrir directement dans un logiciel de tableur comme Microsoft Excel. Ce type de logiciel permet de manipuler directement les données.
Pour ouvrir un fichier CSV depuis Eclipse, il y a deux manières. Soit on double-clique sur le fichier, ce qui l'ouvrira dans l'éditeur du système, soit on fait un clic droit sur le fichier et on choisit l'éditeur de texte pour l'ouvrir dans Eclipse. Selon l'ordinateur utilisé, l'éditeur système sera sûrement MS Excel ou Open Office. Les étapes liées à l'ouverture d'un fichier CSV avec Excel sont présentées en annexes.
3. Première lecture▲
La lecture d'un fichier CSV est réalisée en trois étapes majeures : la lecture bas niveau des données dans un fichier, la prise en compte du format des données et enfin l'utilisation (transformation) des données.
3-A. Helper▲
Dans le cadre de la lecture bas niveau du contenu d'un fichier CSV en Java, on doit manipuler un objet File. Le fichier CSV est une ressource du programme identifiée et accédée à l'aide de cet objet File.
La recherche/récupération d'une ressource sur le disque dur est une fonctionnalité récurrente pour un logiciel de lecture CSV. Je l'ai donc programmée de manière simplifiée et factorisée dans un « helper ».
public class CsvFileHelper {
public static String getResourcePath(String fileName) {
final File f = new File("");
final String dossierPath = f.getAbsolutePath() + File.separator + fileName;
return dossierPath;
}
public static File getResource(String fileName) {
final String completeFileName = getResourcePath(fileName);
File file = new File(completeFileName);
return file;
}
}private final static String FILE_NAME = "src/test/resources/chien-test-01.csv";
@Test
public void testGetResource() {
// Param
final String fileName = FILE_NAME;
// Result
// ...
// Appel
final File file = CsvFileHelper.getResource(fileName);
// Test
// On sait que le fichier existe bien puisque c'est avec lui qu'on travaille depuis le début.
assertTrue(file.exists());
}L'annotation « @Test » sert à indiquer que la méthode ainsi annotée correspond à un test.
Maintenant qu'on sait récupérer un fichier sur le disque dur, il faut l'ouvrir et en lire les données. Dans la mesure où les données d'un fichier CSV sont organisées par ligne, il est possible d'utiliser des objets Java comme FileReader et BufferedReader qui fonctionnent en couple et, surtout, qui simplifient sensiblement les traitements.
La classe BufferedReader possède notamment la méthode readLine permettant de lire une ligne d'un seul coup, et non caractère par caractère comme ce serait le cas avec un « reader » classique. Java sait détecter les fins de lignes.
public class CsvFileHelper {
public static List<String> readFile(File file) {
List<String> result = new ArrayList<String>();
FileReader fr = new FileReader(file);
BufferedReader br = new BufferedReader(fr);
for (String line = br.readLine(); line != null; line = br.readLine()) {
result.add(line);
}
br.close();
fr.close();
return result;
}
...
}L'objectif de la méthode readFile est de lire un fichier CSV et d'en retourner les lignes sous forme de liste. Cette méthode permet de lire le fichier d'un coup. Le fichier n'est alors plus utile et peut donc être relâché. Les appels aux méthodes close() du FileReader et du BufferedReader servent à libérer les ressources.
La Javadoc de FileReader et de BufferedReader sont proposées en annexes.
@Test
public void testReadFile() {
// Param
final String fileName = FILE_NAME;
// Result
final int nombreLigne = 11;
// Appel
final File file = CsvFileHelper.getResource(fileName);
List<String> lines = CsvFileHelper.readFile(file);
// Test
Assert.assertEquals(nombreLigne, lines.size());
}Bien entendu, la lecture du contenu d'un fichier n'est pas si simple en vrai. Il y a des objets à initialiser, des flux à ouvrir et à fermer, et des exceptions à gérer. Un exemple de méthode readFile avec gestion des exceptions est proposé en annexes.
3-B. Lecture CSV de base▲
Tout au long de cet article, plusieurs versions d'un lecteur CSV sont proposées. Chaque nouvelle version complète la précédente. Pour uniformiser les versions, j'ai créé l'interface CsvFile qui définit en particulier la méthode getData(). Cette dernière renvoie une liste de tableaux où chaque élément (i.e. chaque tableau) de la liste représente une ligne du fichier CSV, et où chaque cellule du tableau correspond à une donnée (i.e. colonne) de la ligne.
public interface CsvFile {
File getFile();
List<String[] > getData();
}public class CsvFile01 implements CsvFile {
public final static char SEPARATOR = ',';
private File file;
private List<String> lines;
private List<String[] > data;
private CsvFile01() {
}
public CsvFile01(File file) {
this.file = file;
// Init
init();
}
private void init() {
lines = CsvFileHelper.readFile(file);
data = new ArrayList<String[] >(lines.size());
String sep = new Character(SEPARATOR).toString();
for (String line : lines) {
String[] oneData = line.split(sep);
data.add(oneData);
}
}
// GETTERS ...
}Dans cette première version, le programme lit toutes les lignes du fichier, sans distinguer les lignes vides, les commentaires, les titres, etc. Cette première version est donc clairement incomplète. Elle contient néanmoins la plupart des éléments importants.
L'ArrayList de la méthode init() est construit directement avec la bonne taille (i.e.lines.size) pour optimiser les traitements. En Java, les listes de type ArrayList sont créées avec une capacité initiale de 10 éléments. Bien entendu, cette capacité augmente au fur et à mesure qu'on ajoute de nouveaux éléments. En donnant la bonne taille dès l'initialisation, on gagne un peu en performances puisque Java n'a pas besoin d'augmenter la taille à chaque nouvel ajout dans la liste. La Javadoc de ArrayList est proposée en annexes.
public class CsvFile01Test {
private static final String FILE_NAME = "src/test/resources/chien-test-01.csv";
private static File file;
@BeforeClass
public static void beforeClass() {
file = CsvFileHelper.getResource(FILE_NAME);
}
@Test
public void testFile() {
// Appel
final CsvFile csvFile = new CsvFile01(file);
final File f = csvFile.getFile();
// Test
assertEquals(file, f);
}
@Test
public void testCsvFile() {
// Result
final int nombreLigne = 11;
// Appel
final CsvFile01 csvFile01 = new CsvFile01(file);
final List<String> lines = csvFile01.getLines();
// Test
assertEquals(nombreLigne, lines.size());
}
@Test
public void testData() {
// Result
final int nombreLigne = 11;
final int nombreColonnes = 4;
// Appel
final CsvFile csvFile = new CsvFile01(file);
final List<String[] > data = csvFile.getData();
// Test
assertEquals(nombreLigne, data.size());
for (String[] oneData : data) {
assertEquals(nombreColonnes, oneData.length);
}
}
}L'annotation « @BeforeClass » sert à indiquer que la méthode ainsi annotée est exécutée juste après le chargement de la classe et avant le premier test de cette classe. L'annotation « @Before » sert à indiquer que la méthode ainsi annotée est exécutée juste avant chaque test. @BeforeClass est exécutée une seule fois tout au début des tests, mais @Before est exécutée à chaque test. @BeforeClass est lancée avant @Before.
4. Utilisation via un DAO▲
Dans un programme, on évite d'accéder directement aux données brutes, notamment pour les lire en base ou depuis un fichier. On préfère travailler avec des objets du domaine/métier (des chiens dans le cadre des exemples de cet article) ou des collections d'objets. Le DAO, pour « Data Acces Object », est fait pour ça.
4-A. Domaine Chien▲
Sans grosse surprise, l'application qui sert de support à cet article traite de chiens. Il faut donc avoir des objets Chien. Ici j'ai créé une interface Chien et son implémentation SimpleChien comme illustré dans le diagramme de classe suivant.
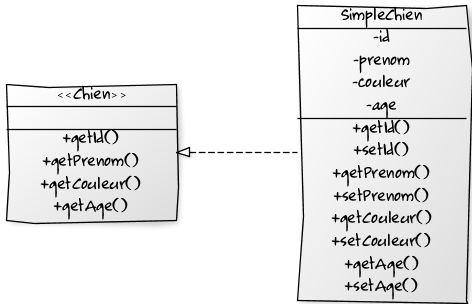
Ce diagramme de classe a été réalisé avec YUML : http://www.yuml.meYUML.ME
Comme indiqué en introduction, certaines équipes auraient plutôt nommé ces objets IChien et ChienImpl
public interface Chien {
Integer getId();
String getPrenom();
String getCouleur();
Integer getAge();
}public class SimpleChien implements Chien {
private Integer id;
private String prenom;
private String couleur;
private Integer age;
@Override
public String toString() {
return prenom + "(" + id + ")";
}
// plus GETTERS / SETTERS
...
}4-B. DAO▲
À ce stade, il ne reste donc plus qu'à écrire un DAO (Data Access Object) qui sera la partie du programme en charge de la lecture des données. L'interface ChienDao propose un contrat de service sans préciser où et/ou comment sont chargées/trouvées les données. Cette première version ne contient qu'une seule méthode, findAllChiens(), qui renvoie la liste complète des chiens (sous forme d'objet Chien) gérée par le programme.
public interface ChienDao {
List<Chien> findAllChiens();
}L'implémentation proposée, ci-dessous, est évidemment conçue autour des fichiers CSV et utilise le lecteur CsvFile présenté plus haut. Toutefois, rien n'empêcherait d'avoir une version utilisant une base de données (DatabaseChienDao) et répondant aux mêmes contrats de service. Un exemple simplifié d'un tel DAO est proposé en annexes.
L'écriture de la première implémentation de ChienDao peut se faire étape par étape, ce qui est proposé dans la suite. Tout d'abord, il faut créer la classe CsvChienDao1 implémentant ChienDao et s'assurer qu'elle compile, en ajoutant les méthodes définies dans l'interface, quitte à les laisser « vides ».
Dans cet article, j'ai clairement fait le choix d'utiliser des
DAO « avec état », c'est-à-dire des objets qui conservent des informations en mémoire.
public class CsvChienDao1 implements ChienDao{
@Override
public List<Chien> findAllChiens() {
List<Chien> chiens = new ArrayList<Chien>();
// Du code ici...
return chiens;
}
}Une fois que la classe compile, on peut écrire le (ou les) constructeurs. Ici, le constructeur sans argument a été marqué private. L'idée est d'avoir un constructeur public qui prend obligatoirement un fichier en paramètre. Ce constructeur en profite pour créer l'objet CsvFile en charge de lire le fichier.
public class CsvChienDao1 implements ChienDao {
private File file;
private CsvFile csvFile;
private CsvChienDao1() {
super();
}
public CsvChienDao1(File file) {
this();
this.file = file;
this.csvFile = new CsvFile01(file);
}
...À partir de là, on peut commencer à écrire le code « intéressant » du DAO. L'algo est relativement cours. La lecture à proprement parler du fichier a été faite depuis le constructeur (par csvFile) et il ne reste qu'à parcourir la liste fournie par l'objet CsvFile et à en convertir les données.
@Override
public List<Chien> findAllChiens() {
List<Chien> chiens = new ArrayList<Chien>();
List<String[]> data = csvFile.getData();
for(String[] oneData : data) {
Chien chien = tabToChien(oneData);
chiens.add(chien);
}
return chiens;
}private Chien tabToChien(String[] tab) {
SimpleChien chien = new SimpleChien();
chien.setId(Integer.parseInt(tab[0]));
chien.setPrenom(tab[1]);
chien.setCouleur(tab[2]);
chien.setAge(Integer.parseInt(tab[3]));
return chien;
}Sans grosse surprise, cette première version provoque des exceptions puisqu'on essaie de convertir aussi les titres en Integer… Il faut donc sauter la première ligne, contenant les titres, ce qui peut se faire de multiples façons.
@Override
public List<Chien> findAllChiens() {
final List<Chien> chiens = new ArrayList<Chien>();
final List<String[]> data = csvFile.getData();
final List<String[]> dataSansTitre = data; // juste data
dataSansTitre.remove(0);
for(String[] oneData : dataSansTitre) {
final Chien chien = tabToChien(oneData);
chiens.add(chien);
}
return chiens;
}public class CsvChienDao1Test {
private static final String FILE_NAME = "src/test/resources/chien-test-01.csv";
private static File file;
private static ChienDao chienDao;
@BeforeClass
public static void beforeClass() {
file = CsvFileHelper.getResource(FILE_NAME);
chienDao = new CsvChienDao1(file);
}
@Test
public void testFindAllChiens() {
// Param
// ...
// Result
final int nombreChien = 10;
// Appel
List<Chien> chiens = chienDao.findAllChiens();
// Test
assertEquals(nombreChien, chiens.size());
}
@Test
public void testIdefix() {
// Param
final String prenom = "Idefix";
// Result
final Integer id = 8;
// Appel
List<Chien> chiens = chienDao.findAllChiens();
Chien idefix = null;
for (Chien chien : chiens) {
if (chien.getPrenom().equals(prenom)) {
idefix = chien;
break;
}
}
// Test
assertNotNull(idefix);
assertEquals(id, idefix.getId());
}
}Dans un vrai programme, la classe CsvChienDao1 aurait sans doute été conçue sous la forme d'un singleton. Le code ressemblerait alors à la classe CsvChienDao1WithSingleton, proposée en annexes. D'ailleurs, pour aller plus loin, dans un vrai programme, le DAO aurait été sans état (i.e. stateless) et les informations auraient été conservées dans un objet dédié.
5. Ligne de titre▲
Comme entrevu dans les chapitres précédents, la première ligne des fichiers CSV est souvent une ligne de titre. Les éléments de cette ligne sont, grosso modo, les entêtes des colonnes. Il est donc intéressant pour notre lecteur CSV qu'il sache traiter ce type d'information. En outre, les fichiers CSV peuvent contenir des lignes vides et des commentaires dont il ne faudra donc pas tenir compte.
# Fichier avec la liste des chiens du magasin
# Propriété de Thierry
# Titres : id, Prénom, Couleur et Age.
Id,Prénom,Couleur,Age
1,Titi,Jaune,5
2,Médor,Noir,10
3,Pitié,Noir,5
4,Juju,Gris,5
5,Vanille,Blanc,7
6,Chocolat,Marron,12
7,Milou,Blanc,3
8,Idefix,Blanc,14
9,Pluto,Jaune,17
10,Dingo,Roux,1On complète l'interface avec la méthode getTitles() qui renvoie la liste des titres/entêtes. De la même manière que la méthode getData() renvoie une liste de tableaux, la méthode getTitles() renvoie également un tableau dont la taille doit (en toute logique) correspondre à celle des tableaux de la liste.
public interface CsvFile {
File getFile();
List<String[] > getData();
String[] getTitles();
}public class CsvFile02 implements CsvFile {
...
private String[] titles;
...
private void init() {
lines = CsvFileHelper.readFile(file);
data = new ArrayList<String[] >(lines.size());
String regex = new Character(SEPARATOR).toString();
boolean first = true;
for (String line : lines) {
// Suppression des espaces de fin de ligne
line = line.trim();
// On saute les lignes vides
if (line.length() == 0) {
continue;
}
// On saute les lignes de commentaire
if (line.startsWith("#")) {
continue;
}
String[] oneData = line.split(regex);
if (first) {
titles = oneData;
first = false;
} else {
data.add(oneData);
}
}
}
...
public String[] getTitles() {
return titles;
}
}On profite de cette seconde version pour améliorer la lecture des lignes, en plus de distinguer les lignes de titre. On va aussi écarter les lignes vides et/ou de commentaire.
private static final String FILE_NAME = "src/test/resources/chien-test-02.csv";
...
@Test
public void testData() {
// Result
final int nombreLigne = 10;
final int nombreColonnes = 4;
// Appel
final CsvFile csvFile = new CsvFile02(file);
final List<String[] > data = csvFile.getData();
// Test
assertEquals(nombreLigne, data.size());
for (String[] oneData : data) {
assertEquals(nombreColonnes, oneData.length);
}
}
@Test
public void testTitle() {
// Result
final int nombreColonnes = 4;
// Appel
final CsvFile csvFile = new CsvFile02(file);
final String[] title = csvFile.getTitles();
// Test
assertEquals(nombreColonnes, title.length);
}Grâce à la séparation des titres et des données, le DAO peut se simplifier, puisqu'il n'y a plus besoin de filtrer la ligne de titre.
public class CsvChienDao2 implements ChienDao {
...
public CsvChienDao2(File file) {
this.csvFile = new CsvFile02(file);
}
@Override
public List<Chien> findAllChiens() {
final List<Chien> chiens = new ArrayList<Chien>();
final List<String[] > data = csvFile.getData();
for (String[] oneData : data) {
final Chien chien = tabToChien(oneData);
chiens.add(chien);
}
return chiens;
}
...
}6. Données mappées▲
Le chapitre précédent montre comment séparer les lignes de données de la ligne de titre. Ce chapitre va un peu plus loin, en fournissant des colonnes non ordonnées à l'aide de Map. En effet, dans la lecture d'un fichier CSV, ce sont les données qui comptent et non l'ordre des colonnes. D'ailleurs l'habitude quand on utilise JDBC (l'API Java qui permet de se connecter aux bases de données) est de ne pas se soucier de l'ordre des colonnes puisque celles-ci sont repérées par leur nom. Ici, on veut justement reproduire ce comportement.
On complète l'interface avec la méthode getMappedData() qui renvoie les données sous forme de Map, et non plus sous forme de tableau.
public interface CsvFile {
File getFile();
List<String[] > getData();
String[] getTitles();
List<Map<String,String>> getMappedData();
}public class CsvFile03 implements CsvFile {
...
private List<Map<String, String>> mappedData;
private void init() {
lines = CsvFileHelper.readFile(file);
data = new ArrayList<String[] >(lines.size());
String regex = new Character(SEPARATOR).toString();
boolean first = true;
for (String line : lines) {
...
}
// On mappe les lignes trouvées
mapData();
}
private void mapData() {
mappedData = new ArrayList<Map<String, String>>(data.size());
final int titlesLength = titles.length;
for (String[] oneData : data) {
final Map<String, String> map = new HashMap<String, String>();
for (int i = 0; i < titlesLength; i++) {
final String key = titles[i];
final String value = oneData[i];
map.put(key, value);
}
mappedData.add(map);
}
}
...
public List<Map<String, String>> getMappedData() {
return mappedData;
}
}private static final String FILE_NAME = "src/test/resources/chien-test-02.csv";
...
@Test
public void testMappedData() {
// Result
final int nombreLigne = 10;
final int nombreColonnes = 4;
// Appel
final CsvFile csvFile = new CsvFile03(file);
final List<Map<String, String>> mappedData = csvFile.getMappedData();
// Test
assertEquals(nombreLigne, mappedData.size());
for (Map<String, String> oneMappedData : mappedData) {
assertEquals(nombreColonnes, oneMappedData.size());
}
}Le DAO utilise donc des maps à la place des tableaux pour créer/stoker les objets Chien (cf. méthode mapToChien() qui remplace la méthode tabToChien()).
public class CsvChienDao3 implements ChienDao {
private CsvFile csvFile;
public CsvChienDao3(File file) {
this.csvFile = new CsvFile03(file);
}
@Override
public List<Chien> findAllChiens() {
final List<Chien> chiens = new ArrayList<Chien>();
final List<Map<String, String>> mappedData = csvFile.getMappedData();
for (Map<String, String> map : mappedData) {
final Chien chien = mapToChien(map);
chiens.add(chien);
}
return chiens;
}
private Chien mapToChien(Map<String, String> map) {
final SimpleChien chien = new SimpleChien();
final String id = map.get("Id");
final String prenom = map.get("Prénom");
final String couleur = map.get("Couleur");
final String age = map.get("Age");
chien.setId(Integer.parseInt(id));
chien.setPrenom(prenom);
chien.setCouleur(couleur);
chien.setAge(Integer.parseInt(age));
return chien;
}
}Ce qui est intéressant avec les données mappées, en remplacement des données sous forme de tableau, c'est que l'ordre des colonnes ne compte pas. Cela veut dire que si le format du fichier change, et plus particulièrement l'ordre des colonnes, il n'y aura pas d'impact sur le code du DAO.
On peut aller un peu plus loin en décidant que les clés des maps ne tiendront pas compte des majuscules et des accents par exemple, ce qui peut éliminer des petits problèmes indétectables. Dans la proposition de code suivante, la méthode cleanKey() retourne une telle clé. Elle sert pour insérer une donnée dans la Map mais aussi pour la rechercher.
public class CsvFile03 implements CsvFile {
...
private void mapData() {
...
for (String[] oneData : data) {
final Map<String, String> map = new HashMap<String, String>();
for (int i = 0; i < titlesLength; i++) {
final String key = CsvFileHelper.cleanKey(titles[i]);
final String value = oneData[i];
map.put(key, value);
}
mappedData.add(map);
}
}
...
}public class CsvFileHelper {
public static String cleanKey(String key) {
String cleanKey = key.toLowerCase();
return cleanKey;
}
...
}7. Les autres séparateurs▲
Les fichiers CSV (pour « Coma Separated Values ») sont donc des fichiers dont les lignes contiennent des valeurs séparées par des virgules. Or le choix de la « virgule » comme séparateur de données n'est pas le seul choix possible. En France par exemple, on utilise plutôt le « point-virgule » comme séparateur. Certains éditeurs préfèrent, quant à eux, les « barres » ou les « tabulations ». Bien que ces quatre séparateurs soient les plus utilisés, on peut imaginer que n'importe quel caractère (ou groupe de caractères) peut être employé.
Pourquoi les éditeurs utilisent-ils des séparateurs différents ? Il existe plusieurs éléments de réponse à cette question. Une raison culturelle, et pas des moindres, qui explique l'utilisation de différents séparateurs est l'écriture des nombres à virgule, qui justement nécessitent l'emploi d'une virgule… Dans ce cas, on doit donc utiliser un autre séparateur (comme le point-virgule par exemple) pour éviter les conflits entre la virgule du nombre et la virgule du séparateur.
# Fichier avec la liste des chiens du magasin
# Propriété de Thierry
# Titres id; Prénom; Couleur et Age.
Id;Prénom;Couleur;Age
1;Titi;Jaune;5
2;Médor;Noir;10
3;Pitié;Noir;5
4;Juju;Gris;5
5;Vanille;Blanc;7
6;Chocolat;Marron;12
7;Milou;Blanc;3
8;Idefix;Blanc;14
9;Pluto;Jaune;17
10;Dingo;Roux;17-A. Choix▲
Le choix du séparateur à utiliser a donc un impact fort sur les résultats de l'algo. Dans la suite, on distinguera notamment trois cas : 1) le choix du bon séparateur, tout se passe bien ; 2) le choix du mauvais séparateur, ce qui fait royalement planter le programme ; 3) le choix du mauvais séparateur, mais qui, par chance/hasard, ne fait pas planter le programme, mais donne néanmoins des résultats faux.
public class CsvFile04 implements CsvFile {
public final static char DEFAULT_SEPARATOR = ',';
private char separator = DEFAULT_SEPARATOR;
private File file;
private List<String> lines;
private List<String[] > data;
private String[] titles;
private List<Map<String, String>> mappedData;
private CsvFile04() {
}
public CsvFile04(File file) {
this(file, DEFAULT_SEPARATOR);
}
public CsvFile04(File file, char separator) {
this.file = file;
this.separator = separator;
// Init
init();
}
private void init() {
lines = CsvFileHelper.readFile(file);
data = new ArrayList<String[] >(lines.size());
String regex = new Character(separator).toString();
boolean first = true;
for (String line : lines) {
...
}
mapData();
}
...
}Avec cette nouvelle version, il est donc possible de spécifier le séparateur à utiliser. Bien que n'importe quel caractère, ou chaîne de caractères, puisse faire office de séparateur, j'ai décidé (pour la suite) de restreindre les séparateurs autorisés à une liste prédéfinie.
public final static List<Character> AVAILABLE_SEPARATORS = Collections.unmodifiableList(new ArrayList<Character>(
Arrays.asList(',', ';', '\t', '|')));
private boolean isValidSeparator(char separator) {
return AVAILABLE_SEPARATORS.contains(separator);
}
public CsvFile04(File file, char separator) {
if (file == null) {
throw new IllegalArgumentException("Le fichier file ne peut pas être null");
}
this.file = file;
if(!isValidSeparator(separator)) {
throw new IllegalArgumentException("Le séparateur spécifié n'est pas pris en charge.");
}
this.separator = separator;
// Init
init();
}Les tests de cette version ne diffèrent pas tellement des tests précédents.
public class CsvFile04Test {
private static final String FILE_NAME = "src/test/resources/chien-test-04.csv";
private static File file;
@BeforeClass
public static void beforeClass() {
file = CsvFileHelper.getResource(FILE_NAME);
}
...
@Test(expected = IllegalArgumentException.class)
public void testIllegalSeparator() {
// Param
final char separator = '-';
// Result
// ...
// Appel
final CsvFile csvFile = new CsvFile04(file, separator);
}
@Test
public void testMappedData() {
// Param
final char separator = ';';
// Result
final int nombreLigne = 10;
final int nombreColonnes = 4;
// Appel
final CsvFile csvFile = new CsvFile04(file, separator);
final List<Map<String, String>> mappedData = csvFile.getMappedData();
// Test
assertEquals(nombreLigne, mappedData.size());
for (Map<String, String> oneMappedData : mappedData) {
assertEquals(nombreColonnes, oneMappedData.size());
}
}
}public class CsvChienDao4 implements ChienDao {
public final static char FRENCH_SEPARATOR = ';';
private CsvFile csvFile;
public CsvChienDao4(File file) {
if (file == null) {
throw new IllegalArgumentException("Le fichier file ne peut pas être null");
}
this.csvFile = new CsvFile04(file, FRENCH_SEPARATOR);
}
...
}Le parti pris (afin de simplifier l'exemple) de cette version du DAO est d'utiliser le point-virgule comme séparateur.
public class CsvChienDao4Test {
private static final String FILE_NAME = "src/test/resources/chien-test-04.csv";
private static File file;
private static ChienDao chienDao;
@BeforeClass
public static void beforeClass() {
file = CsvFileHelper.getResource(FILE_NAME);
chienDao = new CsvChienDao4(file);
}
...
@Test
public void testFindAllChiens() {
// Param
// ...
// Result
final int nombreChien = 10;
// Appel
List<Chien> chiens = chienDao.findAllChiens();
for (Chien chien : chiens) {
System.out.println(chien);
}
// --> Titi(1)
// --> Médor(2)
// --> Pitié(3)
// --> Juju(4)
// --> Vanille(5)
// --> Chocolat(6)
// --> Milou(7)
// --> Idefix(8)
// --> Pluto(9)
// --> Dingo(10)
// Test
assertEquals(nombreChien, chiens.size());
}
...
}7-B. Autoselection du bon séparateur▲
Il arrive très souvent qu'on ne connaisse pas à l'avance le bon séparateur à utiliser pour lire un fichier CSV. Les Anglais utilisent généralement la virgule, les Français préfèrent le point-virgule qui ne pose pas de problème avec le format des nombres, tandis que certains projets ont fait le choix du pipe ou de la tabulation, etc.
Il existe plusieurs manières de « deviner » le bon séparateur à utiliser. Voici quelques propositions. Dans tous les cas, il faut lire les lignes et tenter d'analyser les contenus. On peut ainsi parcourir toutes les lignes ou se contenter des N premières. Dans la mesure où un « vrai » fichier CSV peut être très volumineux, je préfère me concentrer sur les premières lignes seulement. Ce choix n'engage que moi et les codes proposés le sont purement à titre d'exemple.
Le principe de la première version est de lire les cinq (ce nombre peut être paramétré) premières lignes et de compter le nombre d'occurrences de chacun des séparateurs possibles. Le meilleur candidat est alors celui qui donne les mêmes résultats sur toutes les lignes. Il faut bien entendu exclure les zéros.
public class CsvFile05 implements CsvFile {
public final static char DEFAULT_SEPARATOR = ',';
public final static List<Character> AVAILABLE_SEPARATORS = Collections.unmodifiableList(new ArrayList<Character>(
Arrays.asList(',', ';', '\t', '|')));
private boolean autoDetectSeparatorMode = false;
private int numberOfLinesForAutoDetectSeparator = 5;
private char separator = DEFAULT_SEPARATOR;
private List<String> lines;
private List<String> cleanedLines;
...
public CsvFile05(File file) {
this(file, DEFAULT_SEPARATOR);
}
public CsvFile05(File file, char separator) {
this(file, separator, false);
}
public CsvFile05(File file, char separator, boolean autoDetectSeparatorMode) {
if (file == null) {
throw new IllegalArgumentException("Le fichier file ne peut pas être null");
}
this.file = file;
if (!autoDetectSeparatorMode) {
if (!isValidSeparator(separator)) {
throw new IllegalArgumentException("Le séparateur spécifié n'est pas pris en charge.");
}
this.separator = separator;
}
this.autoDetectSeparatorMode = autoDetectSeparatorMode;
// Init
init();
}
public Character selectBestSeparator() {
if (lines.size() == 0) {
// Exception ?...
}
// Ajustement du nombre de lignes dispo
if (cleanedLines.size() < numberOfLinesForAutoDetectSeparator) {
numberOfLinesForAutoDetectSeparator = cleanedLines.size();
}
List<Character> reste = new ArrayList<Character>();
for (Character separator : AVAILABLE_SEPARATORS) {
int previous = 0;
boolean isGoodCandidate = false;
for (int i = 0; i < numberOfLinesForAutoDetectSeparator; i++) {
int compte = compterSeperateurs(cleanedLines.get(i), separator);
if (compte == 0) {
// pas de séparateur dans cette ligne
isGoodCandidate = false;
break;
}
if (compte != previous && previous != 0) {
// pas le même nombre de séparateurs que la ligne précédente
isGoodCandidate = false;
break;
}
previous = compte;
isGoodCandidate = true;
}
if (isGoodCandidate) {
reste.add(separator);
}
}
if (reste.isEmpty()) {
// Exception ? aucun candidat
}
if (1 < reste.size()) {
// Exception ? trop de candidats
}
return reste.get(0);
}
public int compterSeperateurs(String line, char separator) {
int number = 0;
int pos = line.indexOf(separator);
while (pos != -1) {
number++;
line = line.substring(pos + 1);
pos = line.indexOf(separator);
}
return number;
}
private boolean isValidSeparator(char separator) {
return AVAILABLE_SEPARATORS.contains(separator);
}
private void init() {
lines = CsvFileHelper.readFile(file);
cleanedLines = new ArrayList<String>();
for (String line : lines) {
// Suppression des espaces de fin de ligne
line = line.trim();
// On saute les lignes vides
if (line.length() == 0) {
continue;
}
// On saute les lignes de commentaire
if (line.startsWith("#")) {
continue;
}
cleanedLines.add(line);
}
if (autoDetectSeparatorMode) {
this.separator = selectBestSeparator();
}
data = new ArrayList<String[] >(cleanedLines.size());
String regex = new Character(separator).toString();
boolean first = true;
for (String line : cleanedLines) {
...
}
mapData();
}
...
}C'est ici que l'on voit pourquoi j'utilise une List et non un Set pour définir la liste des séparateurs valides AVAILABLE_SEPARATORS. En effet, l'ordre de cette liste donne une sorte de priorité utilisée par l'algo. Le premier séparateur qui semble bon sera choisi. Or il n'est pas impossible que deux séparateurs aient l'air valides en même temps, d'où le besoin d'un ordonnancement.
private static final String FILE_NAME = "src/test/resources/chien-test-04.csv";
@BeforeClass
public static void beforeClass() {
file = CsvFileHelper.getResource(FILE_NAME);
}
@Test
public void testCompterSeperateurs() {
// Param
final char separator = ',';
final String line = "1,Titi,Jaune,5";
// Result
final int nombre = 3;
// Appel
final CsvFile05 csvFile = new CsvFile05(file, separator, true);
final int compte = csvFile.compterSeperateurs(line, separator);
// Test
assertEquals(nombre, compte);
}
@Test
public void testSelectBestSeparator() {
// Param
// ..
// Result
final Character separator = ';';
// Appel
final CsvFile05 csvFile = new CsvFile05(file, separator, true);
final Character separatorCalcule = csvFile.selectBestSeparator();
// Test
assertEquals(separator, separatorCalcule);
}
@Test
public void testMappedData() {
// Param
final char separator = ';';
// Result
final int nombreLigne = 10;
final int nombreColonnes = 4;
// Appel
final CsvFile csvFile = new CsvFile05(file, separator, true);
final List<Map<String, String>> mappedData = csvFile.getMappedData();
// Test
assertEquals(nombreLigne, mappedData.size());
for (Map<String, String> oneMappedData : mappedData) {
assertEquals(nombreColonnes, oneMappedData.size());
}
}Le DAO (CsvChienDao5) et son test (CsvChienDao5Test) correspondant à l'utilisation de cette version du CsvFile (CsvFile05) ne sont pas reproduits dans ce document, mais sont disponibles dans le Zip.
Le principe de la seconde version est de ne compter les occurrences que pour la ligne de titre (i.e. la première) et pour la deuxième ligne. On fait le compte dans l'ordre des séparateurs (d'où la List et non un Set) et on s'arrête dès que cela correspond. L'idée conductrice est que les titres ne contiennent normalement pas de données bizarres.
L'algorithme utilisé pour déterminer le bon séparateur dans CsvFile05 peut être réutilisé à moindre coût pour cette nouvelle version, puisqu'elle fait déjà ce qu'il faut (ce qui d'ailleurs semble valider que cette stratégie ait du sens).
public class CsvFile06 implements CsvFile {
...
public Character selectBestSeparator() {
if (cleanedLines.size() < 2) {
// Exception ?...
}
for (Character separator : AVAILABLE_SEPARATORS) {
final String ligneTitre = cleanedLines.get(0);
final String ligne1 = cleanedLines.get(1);
final int compteLigneTitre = compterSeperateurs(ligneTitre, separator);
final int compteLigne1 = compterSeperateurs(ligne1, separator);
if (compteLigneTitre == 0 || compteLigne1 == 0) {
continue;
}
if (compteLigneTitre == compteLigne1) {
return separator;
}
}
return null;
}
...Le test de CsvFile06 (i.e. CsvFile06Test) ainsi que son DAO est disponible dans le Zip.
Les stratégies proposées ici sont loin d'être parfaites. Il faut les considérer comme de simples illustrations.
8. Données entourées de guillemets▲
Il peut arriver (souvent) qu'un des champs du fichier CSV contienne le « séparateur ». Par exemple, un nombre à virgule (3,14) contient le caractère virgule. Quand un champ contient le séparateur (virgule, point-virgule, etc.), il est obligatoire d'ajouter des guillemets autour du champ pour que le séparateur soit échappé (c'est-à-dire ne soit pas pris en compte).
# Fichier avec la liste des chiens du magasin
# Propriété de Thierry
# Titres id; Prénom; Couleur et Age.
"Id";"Prénom";"Couleur";"Age"
"1";"Titi";"Jaune";"5"
"2";"Médor";"Noir";"10"
"3";"Pitié";"Noir";"5"
"4";"Juju";"Gris";"5"
"5";"Vanille";"Blanc";"7"
"6";"Chocolat";"Marron";"12"
"7";"Milou";"Blanc";"3"
# La ligne suivante (Idefix) a trois couleurs avec un point-virgule dedans
"8";"Idefix";"Blanc; noir et beige";"14"
"9";"Pluto";"Jaune";"17"
10;Dingo;Roux;1Dans le fichier « chien-test-07b.csv », la ligne « Idéfix » possède un champ qui contient le séparateur (i.e. le point-virgule). Du coup tous les champs du fichier sont entourés de guillemets. On pourrait penser que cette stratégie est bien pratique, mais elle alourdit inutilement le fichier CSV et le rend illisible. En outre ce n'est pas l'affaire de notre « reader CSV » puisqu'il doit lire les fichiers qu'on lui donne et n'a pas la main sur leur création.
Des logiciels comme Open Office entourent systématiquement tous les champs avec des guillemets, même lorsque cela n'est pas nécessaire.
En réalité, seule la ligne « Idéfix » a besoin de guillemets.
# Fichier avec la liste des chiens du magasin
# Propriété de Thierry
# Titres id; Prénom; Couleur et Age.
Id;Prénom;Couleur;Age
1;Titi;Jaune;5
2;Médor;Noir;10
3;Pitié;Noir;5
4;Juju;Gris;5
5;Vanille;Blanc;7
6;Chocolat;Marron;12
7;Milou;Blanc;3
# La ligne suivante (Idefix) a trois couleurs avec un point-virgule dedans
8;Idefix;"Blanc; noir et beige";14
9;Pluto;Jaune;17
10;Dingo;Roux;1Cette nouvelle contrainte nous conduit à utiliser des expressions régulières (regex) plus complexes qu'un simple séparateur.
public class CsvFile07 extends AbstractAdvanceCsvFile {
public CsvFile07(File file) {
if (file == null) {
throw new IllegalArgumentException("Le fichier file ne peut pas être null");
}
this.file = file;
if (!isValidSeparator(separator)) {
throw new IllegalArgumentException("Le séparateur spécifié n'est pas pris en charge.");
}
// Init
init();
}
private void init() {
lines = CsvFileHelper.readFile(file);
cleanLines();
data = new ArrayList<String[] >(cleanedLines.size());
final String regex = "(^|(?<=;))([^\";])*((?=;)|$)|((?<=^\")|(?<=;\"))([^\"]|\"\")*((?=\";)|(?=\"$))";
Pattern p = Pattern.compile(regex);
boolean first = true;
for (String line : cleanedLines) {
Matcher m = p.matcher(line);
List<String> temp = new ArrayList<String>();
while (m.find()) {
temp.add(m.group());
}
String[] oneData = listToArray(temp);
if (first) {
titles = oneData;
first = false;
} else {
data.add(oneData);
}
}
mapData();
}
private String[] listToArray(List<String> liste) {
String[] oneData = new String[liste.size()];
for (int i = 0; i < oneData.length; i++) {
oneData[i] = liste.get(i);
}
return oneData;
}
// GETTERS
}Ce bout de code apporte des nouveautés avec l'utilisation des classes Pattern et Matcher du JDK. Ces classes permettent de travailler avec une « vraie » regex et non pas simplement un char comme dans les versions précédentes.
public class CsvFile07 extends AbstractAdvanceCsvFile {
...
private void init() {
...
final String regex = "(^|(?<=;))([^\";])*((?=;)|$)|((?<=^\")|(?<=;\"))([^\"]|\"\")*((?=\";)|(?=\"$))";
Pattern p = Pattern.compile(regex);
for (String line : cleanedLines) {
Matcher m = p.matcher(line);
...
while (m.find()) {
temp.add(m.group());
}
...
}
mapData();
}
...
}Il y a un article d'introduction aux regex sur developpez.comLes regex sur developpez.com, écrit par « Cyberzoide », que je vous invite à consulter.
public class CsvFile07cTest {
private static final String FILE_NAME = "src/test/resources/chien-test-07c.csv";
@Test
public void testMappedData() {
// Param
// Result
final int nombreLigne = 10;
final int nombreColonnes = 4;
// Appel
final CsvFile csvFile = new CsvFile07(file);
final List<Map<String, String>> mappedData = csvFile.getMappedData();
List<String[] > data = csvFile.getData();
for(String[] oneData:data) {
for(String s:oneData) {
System.out.println(s);
}
System.out.println("--------");
}
// Test
assertEquals(nombreLigne, mappedData.size());
for (Map<String, String> oneMappedData : mappedData) {
assertEquals(nombreColonnes, oneMappedData.size());
}
}
}Dans cette version, la classe n'offre pas le choix du séparateur. Elle impose le point-virgule. Toutefois, on peut améliorer le programme pour que la regex prenne en compte un séparateur spécifique.
private void init() {
...
// "(^|(?<=;))([^\";])*((?=;)|$)|((?<=^\")|(?<=;\"))([^\"]|\"\")*((?=\";)|(?=\"$))";
final String regex = "(^|(?<=" + separator + "))([^\"" + separator + "])*((?=" + separator
+ ")|$)|((?<=^\")|(?<=" + separator + "\"))([^\"]|\"\")*((?=\"" + separator + ")|(?=\"$))";
Pattern p = Pattern.compile(regex);
...
}On peut également laisser le programme deviner seul le bon séparateur, en s'inspirant des algos proposés plus haut.
8-A. Double guillemet▲
Les champs peuvent donc également être délimités par des guillemets. Lorsqu'un champ contient lui-même des guillemets, ils sont doublés afin de ne pas être considérés comme début ou fin du champ.
# Titres id; Prénom; Couleur et Age.
Id;Prénom;Couleur;Age
# Titi a une couleur avec doubles guillemets
1;Titi;"Jaune ""bizarre"" et noir";5
2;Médor;Noir;10
3;Pitié;Noir;5
4;Juju;Gris;5
5;Vanille;Blanc;7
6;Chocolat;Marron;12
7;Milou;Blanc;3
# La ligne suivante (Idefix) a trois couleurs avec un point-virgule dedans
8;Idefix;"Blanc; noir et beige";14
9;Pluto;Jaune;17
10;Dingo;Roux;1Pour traiter le cas du « double guillemet », on peut au choix complexifier l'expression régulière proposée dans CsvFile07 ou faire une mini retouche sur le résultat de l'appel à la fonction « group() ». Pour des raisons de simplicité, c'est cette seconde proposition que j'ai choisie. Attention néanmoins, cette « retouche » fait un traitement sur des String, ce qui est déconseillé dans un programme traitant une grosse quantité de données et ayant besoin de performances avancées.
public class CsvFile08 extends AbstractAdvanceCsvFile {
...
private void init() {
lines = CsvFileHelper.readFile(file);
cleanLines();
data = new ArrayList<String[] >(cleanedLines.size());
final String regex = "(^|(?<=" + separator + "))([^\"" + separator + "])*((?=" + separator
+ ")|$)|((?<=^\")|(?<=" + separator + "\"))([^\"]|\"\")*((?=\"" + separator + ")|(?=\"$))";
Pattern p = Pattern.compile(regex);
boolean first = true;
for (String line : cleanedLines) {
Matcher m = p.matcher(line);
List<String> temp = new ArrayList<String>();
while (m.find()) {
String value = m.group();
value = value.replaceAll("\"\"", "\"");
temp.add(value);
}
String[] oneData = listToArray(temp);
if (first) {
titles = oneData;
first = false;
} else {
data.add(oneData);
}
}
mapData();
}
...
}Le test associé n'est pas présenté ici, car il n'apporte rien de nouveau par rapport à CsvFile07Test. Il est néanmoins fourni dans le Zip.
8-B. Valeurs sur plusieurs lignes▲
Les champs peuvent contenir des retours à la ligne, par exemple si le champ correspond à un article de journal composé de plusieurs paragraphes. Dans ce cas, le champ doit être entouré de guillemets.
# Titres id; Prénom; Couleur et Age.
Id;Prénom;Couleur;Age
# Titi a une couleur avec doubles guillemets
1;Titi;"Jaune ""bizarre""";5
2;Médor;Noir;10
3;Pitié;Noir;5
4;Juju;Gris;5
5;Vanille;Blanc;7
6;Chocolat;Marron;12
# Le prénom de Milou est sur plusieurs lignes
7;"Milou
Chien de Tintin
Ami du Capitaine Addock";Blanc;3
# La ligne suivante (Idefix) a trois couleurs avec un point-virgule dedans
8;Idefix;"Blanc; noir et beige";14
9;Pluto;Jaune;17
10;Dingo;Roux;1La prise en compte des champs sur plusieurs lignes est incompatible avec le plus gros des codes proposés plus haut puisque ceux-ci traitent les lignes une par une. Si on veut continuer d'utiliser les regex, on doit donc lire tout le fichier d'un coup, ce qui peut se faire en concaténant les lignes lues à partir de la liste fournie par readFile() ou en écrivant une méthode dédiée.
Il est possible aussi de traiter les champs en même temps qu'on lit le fichier, en écrivant des structures de contrôle (if, switch) pour gérer chaque caractère, notamment les guillemets ouvrant ou fermant, les slash, les guillemets précédés de slash, etc. Il y a grosso modo deux manières de traiter cette piste. Soit on lit tout le fichier, dont on place le contenu dans un String, puis on traite chaque caractère de ce String, soit on lit le fichier caractère par caractère et on en profite pour traiter ce caractère à la volée.
Pour lire un fichier entier, on utilise un (mauvais) code ressemblant au suivant.
public static String readFullFile(File file) {
StringBuilder sb = new StringBuilder();
FileReader reader = new FileReader(file);
char[] buffer = new char[2048];
int nb = 0;
while ((nb = reader.read(buffer)) > 0) {
sb.append(buffer, 0, nb);
}
reader.close();
return sb.toString();
}Ici j'utilise un « buffer » qui fait globalement le même travail que le BufferedReader utilisé plus haut, pour des raisons évidentes de performances. Du coup, autant reprendre le code de readFile() et concaténer les lignes.
public static String readFullFile(File file) {
final List<String> lines = CsvFileHelper.readFile(file);
StringBuilder sb = new StringBuilder();
for(String line : lines) {
sb.append(line);
sb.append("\n"); // pour recréer le retour à la ligne
}
return sb.toString();
}Il ne reste plus qu'à traiter le String résultat, caractère par caractère. On notera que le fait de n'utiliser que le caractère «
» comme fin de ligne va un peu simplifier les traitements…
public List<String[] > readFileAsStringThenTab(File file) {
final String str = readFullFile(file);
for(int i = 0; i < str.length(); i++) {
char c = str.charAt(i);
// ici traiter le char c...
processChar(c);
}
}Ici, je ne donne pas d'exemple de méthode « processChar(c) », car la seconde approche (traiter les caractères en même temps que la lecture) me parait plus appropriée, notamment avec les gros fichiers.
Pour lire le fichier et traiter les caractères à la volée, il faut revenir à la première solution.
...
reader = new FileReader(file);
for(char c = (char) reader.read(); c != '\0'; c = (char) reader.read() ) {
// ici traiter le char c...
processChar2(c);
}
...Le code de « processChar2(c) » est relativement simple et constitué, comme indiqué plus haut, de structures de contrôle.
9. Optimisation▲
Les codes proposés plus haut ne sont clairement pas performants. Ils font des recherches dans du texte, ce qui est coûteux, qui plus est en utilisant des regex (expressions régulières) complexes.
9-A. Indexation des id dans le DAO à l'aide d'une map▲
De la même manière qu'une base de données indexe ses enregistrements, rien n'interdit au CsvDao d'indexer ses données. Le cas le plus simple est celui de l'id qui est unique. Une simple Map suffit pour traiter ce cas…
public interface ChienDao {
List<Chien> findAllChiens();
Chien findChienById(Integer id);
}Comme il est nécessaire de lire le fichier au moins une fois, on en profite pour mapper les id des chiens au passage. Ceci oblige à réécrire une partie des classes proposées ci-dessus, notamment en créant la classe abstraite AbstractChienDao.
public abstract class AbstractChienDao implements ChienDao {
protected CsvFile csvFile;
private Map<Integer, Chien> chiensMap;
private List<Chien> chiens;
protected Chien tabToChien(String[] tab) {
if (tab == null) {
throw new IllegalArgumentException("Le tableau ne peut pas être null");
}
final SimpleChien chien = new SimpleChien();
chien.setId(Integer.parseInt(tab[0]));
chien.setPrenom(tab[1]);
chien.setCouleur(tab[2]);
chien.setAge(Integer.parseInt(tab[3]));
return chien;
}
protected Chien mapToChien(Map<String, String> map) {
if (map == null) {
throw new IllegalArgumentException("La Map ne peut pas être null");
}
final SimpleChien chien = new SimpleChien();
final String id = map.get("Id");
final String prenom = map.get("Prénom");
final String couleur = map.get("Couleur");
final String age = map.get("Age");
chien.setId(Integer.parseInt(id));
chien.setPrenom(prenom);
chien.setCouleur(couleur);
chien.setAge(Integer.parseInt(age));
return chien;
}
protected List<Chien> findAllChiensByMap() {
if (chiens == null) {
init();
}
return chiens;
}
public Chien findChienById(Integer id) {
if (chiensMap == null) {
init();
}
return chiensMap.get(id);
}
protected void init() {
final List<Map<String, String>> mappedData = csvFile.getMappedData();
// On init avec la bonne taille
chiens = new ArrayList<Chien>(mappedData.size());
chiensMap = new HashMap<Integer, Chien>();
for (Map<String, String> map : mappedData) {
final Chien chien = mapToChien(map);
chiens.add(chien);
chiensMap.put(chien.getId(), chien);
}
}
}public class CsvChienDao10 extends AbstractChienDao implements ChienDao {
private CsvChienDao10() {
}
public CsvChienDao10(File file) {
if (file == null) {
throw new IllegalArgumentException("Le fichier file ne peut pas être null");
}
this.csvFile = new CsvFile06(file, ';', true);
}
@Override
public List<Chien> findAllChiens() {
return findAllChiensByMap();
}
}public class CsvChienDao10Test {
private static final String FILE_NAME = "src/test/resources/chien-test-04.csv";
private static File file;
private static ChienDao chienDao;
@BeforeClass
public static void beforeClass() {
file = CsvFileHelper.getResource(FILE_NAME);
chienDao = new CsvChienDao10(file);
}
@Test
public void testFindAllChiens() {
// Param
// ...
// Result
final int nombreChien = 10;
// Appel
List<Chien> chiens = chienDao.findAllChiens();
for (Chien chien : chiens) {
System.out.println(chien);
}
// --> Titi(1)
// --> Médor(2)
// --> Pitié(3)
// --> Juju(4)
// --> Vanille(5)
// --> Chocolat(6)
// --> Milou(7)
// --> Idefix(8)
// --> Pluto(9)
// --> Dingo(10)
// Test
assertEquals(nombreChien, chiens.size());
}
@Test
public void testFindById() {
// Param
final Integer id = 8;
// Result
final String prenom = "Idefix";
// Appel
Chien chien = chienDao.findChienById(id);
System.out.println(chien);
// --> Idefix(8)
// Tests
assertEquals(prenom, chien.getPrenom());
}
}Dans ce code, la méthode init() est marquée protected et non private pour que le DAO qui hérite de AbstractChienDao puisse lancer l'initialisation des listes sans attendre les éventuels appels aux méthodes « find », par exemple depuis le constructeur. Un développeur peut en effet décider d'effectuer l'initialisation dès le lancement du programme. Le démarrage prend donc plus de temps, mais la fonctionnalité « find » est d'autant plus rapide lorsqu'on l'utilise. En général les développeurs font ce choix au cas par cas.
public class CsvChienDao10AvecPreInit extends AbstractChienDao implements ChienDao {
public CsvChienDao10AvecPreInit(File file) {
...
this.csvFile = new CsvFile06(file, ';', true);
init(); // Initialisation dès le constructeur
}
...
}9-A-1. Indexation des prénoms à l'aide de multimap▲
On peut également indexer les prénoms. Puisqu'ils ne sont pas supposés être uniques, il faut utiliser un mécanisme de MultiMap.
Une multimap, c'est une map de liste ou une map de map. Des frameworks comme Google-Collections offrent des fonctionnalités MultiMap avancées. Toutefois, dans le cadre du ChienDao, une Map spécifique, contenant une liste comme valeur, suffit amplement. J'invite le lecteur à découvrir les fonctionnalités offertes par Google en lisant mon article d'introduction aux Google-Collections sur developpez.comLes Google-Collections sur developpez.com.
public interface ChienDao {
List<Chien> findAllChiens();
Chien findChienById(Integer id);
List<Chien> findChiensByPrenom(String prenom);
}public abstract class AbstractChienDao implements ChienDao {
private Map<String, List<Chien>> chiensMultimapByPrenom;
...
public List<Chien> findChiensByPrenom(String prenom) {
if (chiensMap == null) {
init();
}
return chiensMultimapByPrenom.get(prenom);
}
protected void init() {
...
// On ne connait pas la taille de la multimap à l'avance
chiensMultimapByPrenom = new HashMap<String, List<Chien>>();
for (Map<String, String> map : mappedData) {
...
addChienToMultimap(chien, chiensMultimapByPrenom, chien.getPrenom());
}
}
private void addChienToMultimap(Chien chien, Map<String, List<Chien>> multimap, String key) {
List<Chien> sublist = multimap.get(key);
if (sublist == null) {
sublist = new ArrayList<Chien>();
multimap.put(key, sublist);
}
sublist.add(chien);
}
}# Titres id; Prénom; Couleur et Age.
Id;Prénom;Couleur;Age
1;Titi;Jaune;5
2;Médor;Noir;10
3;Pitié;Noir;5
4;Juju;Gris;5
5;Vanille;Blanc;7
6;Chocolat;Marron;12
7;Milou;Blanc;3
8;Idefix;Blanc;14
9;Pluto;Jaune;17
10;Dingo;Roux;1
# 2nd chien Vanille
11;Vanille;Beige;13public class CsvChienDao11Test {
private static final String FILE_NAME = "src/test/resources/chien-test-11.csv";
private static File file;
private static ChienDao chienDao;
@BeforeClass
public static void beforeClass() {
file = CsvFileHelper.getResource(FILE_NAME);
chienDao = new CsvChienDao10(file);
}
@Test
public void testFindByPrenomChocolat() {
// Param
final String prenom = "Chocolat";
// Result
final int nb = 1;
// Appel
List<Chien> chiens = chienDao.findChiensByPrenom(prenom);
System.out.println(chiens);
// --> [Chocolat(6)]
// Tests
assertEquals(nb, chiens.size());
assertEquals(prenom, chiens.get(0).getPrenom());
}
@Test
public void testFindByPrenomVanille() {
// Param
final String prenom = "Vanille";
// Result
final int nb = 2;
// Appel
List<Chien> chiens = chienDao.findChiensByPrenom(prenom);
System.out.println(chiens);
// --> [Vanille(5), Vanille(11)]
// Tests
assertEquals(nb, chiens.size());
assertEquals(prenom, chiens.get(0).getPrenom());
assertEquals(prenom, chiens.get(1).getPrenom());
}
}Bien entendu, dans un vrai programme, on chercherait plutôt les chiens dont le nom ressemble à celui passé en paramètre, sans forcément tenir compte des majuscules et/ou des accents. Un tel programme aurait même autorisé des mauvais caractères dans le prénom, mais ce n'est pas l'objet de cet article.
De manière générale, on réservera cette technique de « cache » à l'aide de Map aux champs les plus sollicités.
10. Autoreload et multithread▲
Même si ce n'est pas l'objet des fichiers CSV (qui doivent être utilisés pour transmettre des infos et non pour les stocker) on peut imaginer que plusieurs programmes lisent ou modifient un fichier CSV en même temps. Cela pose des questions quant à la gestion des ressources et à la détection des éventuelles modifications (par un autre programme) durant la lecture. Les nouvelles versions de Java-IO (java 7 ou 8) devraient apporter des réponses simples.
11. Écriture▲
L'écriture d'un fichier CSV est simplement l'inverse de la lecture. On peut même dire que c'est plus simple puisqu'on à la main sur tous les paramètres, notamment les formats utilisés. Je vais donc suivre une démarche similaire à celle utilisée pour la lecture, mais en sautant les étapes.
On commence par créer l'interface CsvFileWriter, porteuse des contrats de service qui nous intéressent, puis on peut se concentrer sur une première implémentation.
public interface CsvFileWriter {
void write(List<Map<String, String>> mappedData);
void write(List<Map<String, String>> mappedData, String[] titles);
}public class CsvFileWriter01 implements CsvFileWriter {
private File file;
private char separator;
public CsvFileWriter01(File file) {
this(file, ';');
}
public CsvFileWriter01(File file, char separator) {
this();
if (file == null) {
throw new IllegalArgumentException("Le fichier ne peut pas etre nul");
}
this.file = file;
this.separator = separator;
}
private void writeEmptyFile() {
...
}
@Override
public void write(List<Map<String, String>> mappedData) {
if (mappedData == null) {
throw new IllegalArgumentException("la liste ne peut pas être nulle");
}
if (mappedData.isEmpty()) {
writeEmptyFile();
}
final Map<String, String> oneData = mappedData.get(0);
final String[] titles = new String[oneData.size()];
int i = 0;
for (String key : oneData.keySet()) {
titles[i++] = key;
}
write(mappedData, titles);
}
@Override
public void write(List<Map<String, String>> mappedData, String[] titles) {
if (mappedData == null) {
throw new IllegalArgumentException("la liste ne peut pas être nulle");
}
if (titles == null) {
throw new IllegalArgumentException("les titres ne peuvent pas être nuls");
}
if (mappedData.isEmpty()) {
writeEmptyFile();
}
FileWriter fw = new FileWriter(file);
BufferedWriter bw = new BufferedWriter(fw);
// Les titres
boolean first = true;
for (String title : titles) {
if (first) {
first = false;
} else {
bw.write(separator);
}
write(title, bw);
}
bw.write("\n");
// Les données
for (Map<String, String> oneData : mappedData) {
first = true;
for (String title : titles) {
if (first) {
first = false;
} else {
bw.write(separator);
}
final String value = oneData.get(title);
write(value, bw);
}
bw.write("\n");
bw.close();
fw.close();
}
}
private void write(String value, BufferedWriter bw) throws IOException {
if (value == null) {
value = "";
}
boolean needQuote = false;
if (value.indexOf("\n") != -1) {
needQuote = true;
}
if (value.indexOf(separator) != -1) {
needQuote = true;
}
if (value.indexOf("\"") != -1) {
needQuote = true;
value = value.replaceAll("\"", "\"\"");
}
if(needQuote) {
value = "\"" + value + "\"";
}
bw.write(value);
}
}Ici, c'est bien entendu la méthode write(String, BufferedWriter) qui réalise la partie importante du travail lié au format CSV. Les autres méthodes write(..) se concentrent sur les séparateurs et les éléments techniques.
Les classes FileWriter et BufferedWriter fonctionnent selon les mêmes principes que FileWriter et BufferedWriter, déjà abordées plus haut.
Les Javadocs de FileWriter et de BufferedWriter sont proposées en annexes.
private static final String FILE_NAME = "out/chien-test-out01.csv";
private static File file;
private static CsvFileWriter csvFileWriter;
@BeforeClass
public static void beforeClass() {
file = CsvFileHelper.getResource(FILE_NAME);
csvFileWriter = new CsvFileWriter01(file);
}
private List<Map<String, String>> createMap() {
List<Map<String, String>> data = new ArrayList<Map<String, String>>();
Map<String, String> oneData1 = new HashMap<String, String>();
oneData1.put("Id", "1");
oneData1.put("Prénom", "Idéfix");
oneData1.put("Couleur", "Blanc");
oneData1.put("Age", "15");
data.add(oneData1);
Map<String, String> oneData2 = new HashMap<String, String>();
oneData2.put("Id", "2");
oneData2.put("Prénom", "Milou \"de Tintin\"");
oneData2.put("Couleur", "Blanc");
oneData2.put("Age", "7");
data.add(oneData2);
return data;
}
@Test
public void testWrite() {
// Param
final List<Map<String, String>> data = createMap();
// Resultat attendu
final String[] wantedTitles = { "Age", "Couleur", "Prénom", "Id" };
// Appel
csvFileWriter.write(data);
final CsvFile csvFile = new CsvFile07(file, ';');
final String[] titlesFromFile = csvFile.getTitles();
// Test
// pas d'ordre dans les titres
for (String title : titlesFromFile) {
assertTrue(isInTab(title, wantedTitles));
}
}
@Test
public void testWriteAvecOrdre() {
// Param
final List<Map<String, String>> data = createMap();
final String[] titles = { "Id", "Prénom", "Age", "Couleur" };
// Resultat attendu
final String[] wantedTitles = { "Id", "Prénom", "Age", "Couleur" };
// Appel
csvFileWriter.write(data, titles);
final CsvFile csvFile = new CsvFile07(file, ';');
final String[] titlesFromFile = csvFile.getTitles();
// Test
// L'ordre compte
for (int i = 0; i < wantedTitles.length; i++) {
Assert.assertEquals(wantedTitles[i], titlesFromFile[i]);
}
}Pour réaliser ce test, je pars du principe que le lecteur CsvFile07 a déjà été testé dans les chapitres précédents et qu'on peut s'appuyer dessus pour vérifier le fonctionnement du « writer ».
Pour le DAO, c'est un peu le même principe sauf qu'on travaille directement avec une liste de chiens.
public interface ChienDao {
List<Chien> findAllChiens();
Chien findChienById(Integer id);
List<Chien> findChiensByPrenom(String prenom);
void writeChiens(List<Chien> chiens, File file);
}public class CsvChienDao12 extends AbstractChienDao implements ChienDao {
private CsvFileWriter fileWriter;
...
@Override
public void writeChiens(List<Chien> chiens, File file) {
if (chiens == null) {
throw new IllegalArgumentException("La liste de chien ne peut pas être nulle");
}
if (file == null) {
throw new IllegalArgumentException("Le fichier ne peut pas être nul");
}
fileWriter = new CsvFileWriter01(file);
List<Map<String, String>> mappedData = new ArrayList<Map<String, String>>();
for (Chien chien : chiens) {
Map<String, String> oneData = chienToMap(chien);
mappedData.add(oneData);
}
fileWriter.write(mappedData);
}
private Map<String, String> chienToMap(Chien chien) {
Map<String, String> oneData = new HashMap<String, String>();
oneData.put("Id", chien.getId().toString());
oneData.put("Prénom", chien.getPrenom());
oneData.put("Couleur", chien.getCouleur());
oneData.put("Age", chien.getAge().toString());
return oneData;
}
...
}private static final String FILE_NAME = "out/chien-test-out02.csv";
private static File file;
private static ChienDao chienDao;
@BeforeClass
public static void beforeClass() {
file = CsvFileHelper.getResource(FILE_NAME);
chienDao = new CsvChienDao12();
}
private List<Chien> createChiens() {
List<Chien> chiens = new ArrayList<Chien>();
SimpleChien chien1 = new SimpleChien();
chien1.setId(1);
chien1.setPrenom("Pollux");
chien1.setCouleur("Blanc et vert avec un motif \"anglais\" et des poils gris sur la queue");
chien1.setAge(12);
chiens.add(chien1);
SimpleChien chien2 = new SimpleChien();
chien2.setId(2);
chien2.setPrenom("Lulu");
chien2.setCouleur("Noir;Blanc et jaune");
chien2.setAge(12);
chiens.add(chien2);
return chiens;
}
@Test
public void testWrite() {
// Param
final List<Chien> chiens = createChiens();
// Result
final String[] wantedTitles = { "Age", "Couleur", "Prénom", "Id" };
final int nombreChiens = 2;
// Appel
chienDao.writeChiens(chiens, file);
final CsvFile csvFile = new CsvFile07(file, ';');
final String[] titlesFromFile = csvFile.getTitles();
// Tests
// pas d'ordre dans les titres
for (String title : titlesFromFile) {
assertTrue(isInTab(title, wantedTitles));
}
Assert.assertEquals(csvFile.getData().size(), nombreChiens);
}12. Les frameworks du marché▲
Le web regorge de frameworks dédiés aux fichiers CSV. Certains, comme Open CSV, sont vraiment bons et répondent à des besoins génériques. D'autres sont plus spécialisés, par exemple sur des optimisations particulières.
Les chapitres précédents expliquent les notions de base du CSV, mais le plus simple et le plus efficace reste d'utiliser une librairie toute prête.
12-A. Open Csv▲
Open Csv est une librairie Java sous licence Open source. On la trouve sur le Web à l'adresse http://opencsv.sourceforge.net
Pour utiliser Open CSV dans un projet Maven, il suffit d'ajouter une dépendance dans le Pom.
<dependency>
<groupId>net.sf.opencsv</groupId>
<artifactId>opencsv</artifactId>
<version>2.0</version>
</dependency>Puis comme d'habitude lancer Maven
mvn clean install eclipse:eclipsePour utiliser Open CSV dans le programme sans trop modifier le DAO, il suffit d'utiliser le CSVReader dans notre CsvFile.
public class CsvFile12 extends AbstractAdvanceCsvFile {
private CSVReader reader;
private CsvFile12() {
}
public CsvFile12(File file) {
this(file, DEFAULT_SEPARATOR);
}
public CsvFile12(File file, char separator) {
this.file = file;
this.separator = separator;
// Init
init();
}
private void init() {
reader = new CSVReader(new FileReader(file), separator);
data = new ArrayList<String[] >();
String[] nextLine;
while ((nextLine = reader.readNext()) != null) {
final int size = nextLine.length;
if(size == 0) {
continue;
}
String debut = nextLine[0].trim();
if(debut.length() == 0 && size == 1 ) {
continue;
}
if(debut.startsWith("#")) {
continue;
}
data.add(nextLine);
}
titles = data.get(0);
data.remove(0);
mapData();
}
...
}private static final String FILE_NAME = "src/test/resources/chien-test-11.csv";
@Test
public void testMappedData() {
// Param
final char separator = ';';
// Result
final int nombreLigne = 11;
final int nombreColonnes = 4;
// Appel
final CsvFile csvFile = new CsvFile12(file, separator);
final List<Map<String, String>> mappedData = csvFile.getMappedData();
// List<String[] > data = csvFile.getData();
// Test
assertEquals(nombreLigne, mappedData.size());
for (Map<String, String> oneMappedData : mappedData) {
assertEquals(nombreColonnes, oneMappedData.size());
}
}
@Test
public void testTitles() {
// Param
final char separator = ';';
// Result
String[] wantedTitles = { "Id", "Prénom", "Couleur", "Age" };
// Appel
final CsvFile csvFile = new CsvFile12(file, separator);
final String[] titles = csvFile.getTitles();
for (String title : titles) {
System.out.println(title);
}
// Test
for (int i = 0; i < wantedTitles.length; i++) {
assertEquals(wantedTitles[i], titles[i]);
}
}13. Pour aller plus loin▲
Bien que cet article présente quelques optimisations, il fait l'impasse sur les optimisations importantes et, encore plus, sur l'utilisation des fichiers CSV en fonction de la volumétrie.
En effet, les codes proposés fonctionnent très bien sur des projets modestes, dans lesquels les fichiers CSV ne contiennent que quelques centaines/milliers de lignes. On pensera par exemple aux fichiers CSV disponibles sur le site de la Française des Jeux et donnant les résultats des tirages du Loto, Euro Millions, etc. À raison d'un ou deux tirages (i.e. lignes) par semaine, et pour quelques dizaines d'années d'historique, on est sur des tailles raisonnables, chaque ligne ne comportant qu'une vingtaine de champs. En outre, les applications qui gèrent ce type de données ne nécessitent pas de performances (vitesse, charge mémoire, etc.) élevées.
Au contraire, certaines applications, par exemple dans le domaine de la bourse, utilisent des fichiers CSV multiformats (très) volumineux. J'ai ainsi travaillé sur une application de mise à jour des valeurs de l'ensemble des actions du marché. Les fichiers CSV alors utilisés pesaient des dizaines (voire des centaines dans des cas spéciaux extrêmes) de Mo et devaient être intégrés toutes les cinq minutes, sans ralentir ni surcharger le reste du serveur.
Avec de telles contraintes, on doit monter d'un cran. Mais avant tout il convient de noter que, et c'est valable dans tous les cas, les fichiers CSV doivent servir exclusivement à transférer de l'information, et non au stockage des données. Pourquoi cela ? D'abord parce que, qui dit stockage dit aussi mise à jour. Quand on modifie une ligne d'un fichier CSV, par exemple en modifiant la valeur « 123 » d'un champ par « 123456 » (la taille du champ change), on doit réécrire l'intégralité des lignes suivantes. Si le fichier comporte 25 lignes et qu'on modifie la 3e ligne, on doit réécrire 22 lignes seulement, ce qui est quasi instantané. Si le fichier contient la liste des transactions boursières de Paris, ce sont des centaines et des centaines de milliers de lignes qu'il faudra de nouveau écrire. Dans ce cas, on est très loin des performances qu'on obtiendrait avec une base de données.
Ensuite, il est évident que, dépassé une certaine taille, il n'est plus possible de charger en mémoire l'intégralité d'un fichier CSV et de le traiter plus tard. On est obligé de le traiter en même temps qu'on lit les lignes. Les patterns de lecture des flux à utiliser sont donc relativement différents.
13-A. Trois ans plus tard▲
Edit : Je reviens sur cet article trois ans après l'avoir écrit. Entre temps, la technologie a évolué. La mémoire vive (RAM) des serveurs a été multipliée par quatre, voire plus. Même les postes de développeurs sont de plus en plus équipés de 16 Go de RAM alors que 4 était jusque là le standard. Les capacités des disques durs, et plus généralement des unités de stockage, ont été revues à la hausse. Alors qu'il y a trois ans, l'unité de mesure était encore la centaine de Go (Giga), on parle désormais en To (Tera). En outre, les unités de stockage sans partie mobile, comme les SSD, sont enfin accessibles à des prix compétitifs et offrent des performances incroyables.
Tout cela pourrait encourager les développeurs à ne plus faire d'effort dans leurs programmes. Mais c'est un piège. Au contraire, on manipule de plus en plus de données. On a donc des fichiers CSV de plus en plus gros. Et oui, trois ans plus tard, les fichiers CSV sont toujours présents. Le format JSON a révolutionné le secteur informatique, mais ne répond pas à tous les besoins, notamment dans le cadre d'une forte volumétrie.
L'idéal est de travailler avec des fichiers CSV dont chaque ligne est indépendante des autres, ce qui est souvent le cas. Par exemple, dans mes fichiers des cours des actions, chaque ligne correspond à la valeur d'une action et ne dépend donc pas des autres lignes. Le sens de l'histoire tend à traiter chaque ligne au moment où elle est lue et non plus de lire l'ensemble du fichier d'un coup pour en traiter les lignes plus tard. Des frameworks comme Spring-Batch facilitent ce fonctionnement. Ils recommandent d'ailleurs, pour des raisons évidentes, de traiter les lignes par lots (plus ou moins gros). Ainsi au lieu de traiter un fichier de 10 000 lignes en une seule fois, on préfère le découper en plus petits lots de seulement 1000 lignes chacun. On traitera alors 10 lots. La taille d'un lot dépend bien entendu du sujet d'étude. Mais cela n'est possible que si les lignes sont indépendantes.
En fait, cette méthodologie existait déjà il y a trois ans. Elle était d'ailleurs déjà efficace. Or, l'évolution des processeurs ne tend plus à augmenter la fréquence (exprimée en MHz), mais à multiplier le nombre de cœurs, c'est-à-dire d'unités de calcul/traitement. Les derniers processeurs destinés aux particuliers ont souvent 4 cœurs ou plus, leur permettant donc d'effectuer autant d'opérations en même temps. Pouvoir diviser un fichier CSV en petits lots permet d'utiliser ce nouveau potentiel. Et, disons-le, c'est extrêmement performant.
L'arrivée de Java 7 a permis de vrais gains dans le cadre de la programmation concurrente (i.e. parallèle) et celle de Java 8 (prévue dans quelques semaines) va simplifier l'écriture des programmes dans ce but. Un mot/notion a bien connaitre sera le « Stream ». Je vous conseille de vous y intéresser.
14. Conclusions▲
L'objectif de cet article était de montrer ce qui se cache derrière un sujet aussi simple que les fichiers CSV. Ce sont des notions de base que tout développeur se doit de connaître. Je voulais aller un peu plus loin que la version minimale en proposant des chapitres d'algo et d'optimisation. Or comme on le voit dans ce document, le sujet est réellement complexe.
Les fichiers CSV ne doivent être utilisés que pour la transmission de données. Cet article n'en parle pas beaucoup, mais c'est pourtant un point essentiel. Les techniques présentées plus haut sont à réserver aux fichiers dont la taille reste raisonnable (disons quelques centaines de lignes/données). On pourrait en discuter encore pendant des heures.
Dans tous les cas, il existe de très bonnes librairies (open source) sur le Web et il est recommandé de les utiliser, plutôt que de tout réécrire.
15. Remerciements▲
Je tiens à remercier, en tant qu'auteur de cet article sur les CSV, toutes les personnes qui m'ont aidé et soutenu. Je pense tout d'abord à mes collègues qui subissent mes questions au quotidien, mais aussi à mes contacts et amis du web, dans le domaine de l'informatique ou non, qui m'ont fait part de leurs remarques et critiques. Bien entendu, je n'oublie pas l'équipe de developpez.com qui m'a guidé dans la rédaction de cet article et m'a aidé à le corriger et le faire évoluer, principalement sur le forum.
Plus particulièrement j'adresse mes remerciements, par ordre alphabétique, à ClaudeLELOUP, deltree, Djug, Estelle, Karyne, Hing, hwoarang, Loceka, Nemek, Patriarch24, Romain, sinok, SucreGlace, tchize et william44290.

16. Annexes▲
16-A. Convertir des données CSV dans Excel▲
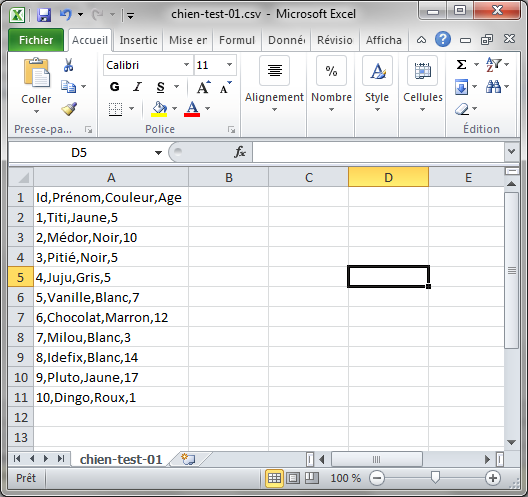
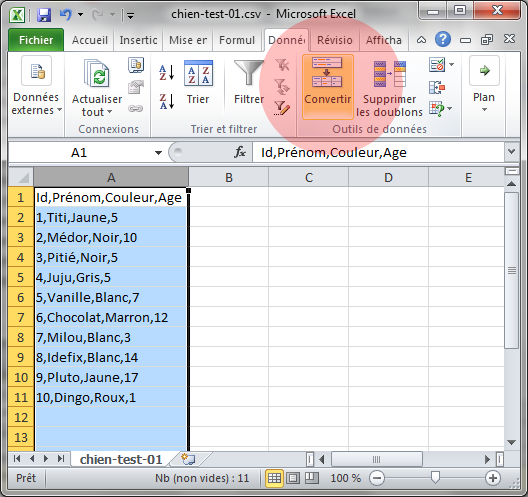
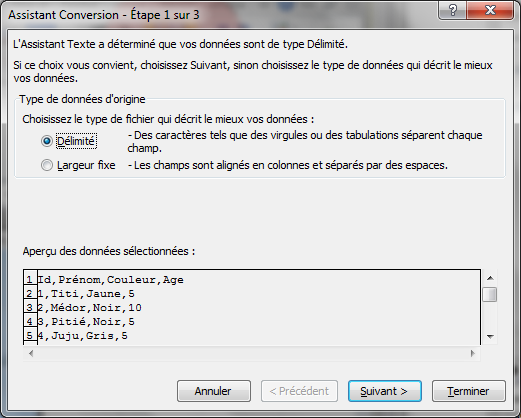
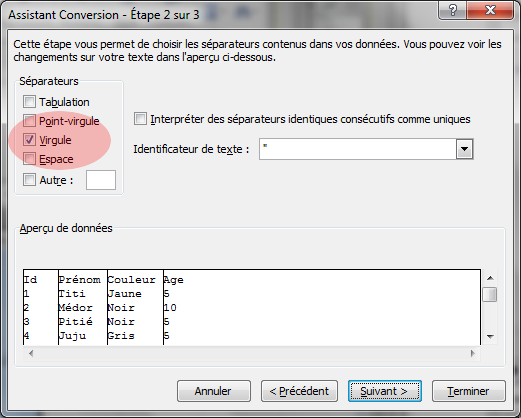
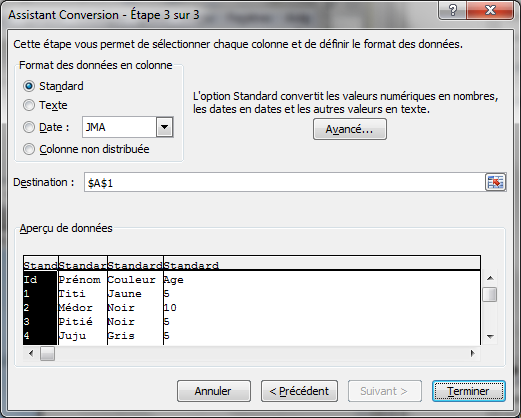
Quand on ouvre un fichier CSV avec Open Office, il faut éviter de sauver les modifications. En effet, Open Office a tendance à modifier le format interne des fichiers CSV, les rendant alors inutilisables. Ce bogue sera sûrement corrigé prochainement. Sans surprise, MS Excel n'a pas ce genre de problème.
16-B. Exemple de DAO en version base de données▲
public class DatabaseChienDao implements ChienDao {
@Override
public List<Chien> findAllChiens() {
final List<Chien> chiens = new ArrayList<Chien>();
Connection con = null;
Statement statement = null;
try {
Class.forName("oracle.jdbc.driver.OracleDriver");
// (2)
con = DriverManager.getConnection("monUrl", "monLogin", "monPassword");
// (3)
String sql = "SELECT * FROM chien ";
// (4)
statement = con.createStatement();
// (5)
ResultSet rs = statement.executeQuery(sql);
while (rs.next()) {
final Chien chien = rsetToChien(rs);
chiens.add(chien);
}
} catch (Exception e) {
// ...
} finally {
try {
if (statement != null) {
statement.close();
}
if (con != null) {
con.close();
}
} catch (Exception e) {
// ...
}
}
return chiens;
}
private Chien rsetToChien(ResultSet rs) {
if (rs == null) {
throw new IllegalArgumentException("Le resultset ne peut pas être null");
}
final SimpleChien chien = new SimpleChien();
try {
final Integer id = rs.getInt("id");
final String prenom = rs.getString("prenom");
final String couleur = rs.getString("color_poil");
final Integer age = rs.getInt("age");
chien.setId(id);
chien.setPrenom(prenom);
chien.setCouleur(couleur);
chien.setAge(age);
} catch (Exception e) {
// ...
}
return chien;
}
}16-C. Helper readFile avec gestion des exceptions▲
public class CsvFileHelper {
public static List<String> readFile(File file) {
if (file == null) {
throw new IllegalArgumentException("Le fichier ne peut pas être null");
}
if (!file.exists()) {
throw new IllegalArgumentException("Le fichier " + file.getName() + " n'existe pas.");
}
final List<String> result = new ArrayList<String>();
FileReader fr = null;
BufferedReader br = null;
try {
fr = new FileReader(file);
br = new BufferedReader(fr);
for (String line = br.readLine(); line != null; line = br.readLine()) {
result.add(line);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
if (br != null) {
try {
br.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (fr != null) {
try {
fr.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
return result;
}
...
}16-D. DAO avec singleton▲
public class CsvChienDao1WithSingleton implements ChienDao {
private File file;
private CsvFile csvFile;
private static CsvChienDao1WithSingleton instance;
private CsvChienDao1WithSingleton() {
}
private CsvChienDao1WithSingleton(File file) {
this.file = file;
this.csvFile = new CsvFile01(file);
}
private static void init(File file) {
instance = new CsvChienDao1WithSingleton(file);
}
public static synchronized CsvChienDao1WithSingleton getInstance(File file) {
if (instance == null) {
init(file);
} else {
final String oldFileName = instance.getFile().getAbsolutePath();
final String newFileName = file.getAbsolutePath();
if (!oldFileName.equals(newFileName)) {
// Si on demande un nouveau fichier
init(file);
}
}
return instance;
}
@Override
public List<Chien> findAllChiens() {
...
}
private Chien tabToChien(String[] tab) {
...
}
public File getFile() {
return file;
}
public void setFile(File file) {
this.file = file;
}
}Comme tout bon singleton, les éléments clés sont, ici, un constructeur privé, une variable d'instance statique et une méthode d'obtention d'instance également statique. Dans cet exemple j'ai aussi fait le choix de marquer la méthode getInstance comme synchronisée. On notera que la littérature propose plusieurs solutions pour synchroniser un singleton, mais que le mot clé synchronized est en définitive le plus simple et, sans doute, le plus efficace.
Ce code utilise l'instruction file.getAbsolutePath(), car la méthode getAbsolutePath() renvoie le nom complet du fichier, à partir de la racine, avec ses différents dossiers. La méthode getName() quant à elle ne renvoie que le nom du fichier, sans préciser dans quel dossier il se trouve. L'utilisation de getAbsolutePath(), et non de getName(), évite de confondre deux fichiers différents dans des dossiers différents, mais portant le même nom. Une illustration (une classe de test) de cette différence est fournie dans le Zip sous le nom « FileNameTest.java »
Pour tester ce singleton, il suffit de reprendre le test CsvChienDao1Test et de changer une seule ligne.
public class CsvChienDao1WithSingletonTest {
...
@BeforeClass
public static void beforeClass() {
file = CsvFileHelper.getResource(FILE_NAME);
chienDao = CsvChienDao1WithSingleton.getInstance(file);
}
...
}Le problème, avec le code proposé, ci-dessus, est que chaque nouveau fichier passé à getInstance écrase les valeurs chargées à partir du fichier précédent. Or il est légitime de supposer que le chargement des données contenues dans le fichier précédent a consommé une grosse quantité de ressources (CPU, time, etc.) On peut alors complexifier le singleton pour qu'il gère plusieurs fichiers, par exemple à l'aide d'une Map. Je donne ici un exemple avec la classe CsvChienDao1WithSingletonMultiFile, mais je conseille toutefois de ne pas abuser de cette pratique.
public class CsvChienDao1WithSingletonMultiFile implements ChienDao {
private CsvFile csvFile;
private static Map<String, CsvChienDao1WithSingletonMultiFile> instanceMap
= new HashMap<String, CsvChienDao1WithSingletonMultiFile>();
private CsvChienDao1WithSingletonMultiFile() {
}
private CsvChienDao1WithSingletonMultiFile(File file) {
this.csvFile = new CsvFile01(file);
}
private static void init(File file) {
CsvChienDao1WithSingletonMultiFile instance = new CsvChienDao1WithSingletonMultiFile(file);
instanceMap.put(file.getgetAbsolutePath(), instance);
}
public static synchronized CsvChienDao1WithSingletonMultiFile getInstance(File file) {
CsvChienDao1WithSingletonMultiFile instance = instanceMap.get(file.getName());
if (instance == null) {
init(file);
}
return instance;
}
...
}Cette Map est intéressante, mais il faut se demander comment on va accéder aux données de chaque fichier. En effet, le contrat de service défini dans l'interface ChienDao, et en particulier dans le cadre de la méthode findAllChiens(), n'utilise pas de fichier (ni de nom de fichier) pour sélectionner une des entrées de la Map. Il faut donc trouver un truc, mais ce n'est pas l'objet de ce document…
16-E. Extraits de Javadocs▲
Voici ce que dit la Javadoc au sujet de FileReader : « Convenience class for reading character files. The constructors of this class assume that the default character encoding and the default byte-buffer size are appropriate. To specify these values yourself, construct an InputStreamReader on a FileInputStream. FileReader is meant for reading streams of characters. For reading streams of raw bytes, consider using a FileInputStream. »
Voici ce que dit la Javadoc au sujet de BufferedReader : « Reads text from a character-input stream, buffering characters so as to provide for the efficient reading of characters, arrays, and lines. The buffer size may be specified, or the default size may be used. The default is large enough for most purposes. In general, each read request made of a Reader causes a corresponding read request to be made of the underlying character or byte stream. It is therefore advisable to wrap a BufferedReader around any Reader whose read() operations may be costly, such as FileReaders and InputStreamReaders. [..] Without buffering, each invocation of read() or readLine() could cause bytes to be read from the file, converted into characters, and then returned, which can be very inefficient. Programs that use DataInputStreams for textual input can be localized by replacing each DataInputStream with an appropriate BufferedReader. »
Voici ce que dit la Javadoc au sujet de ArrayList : « public ArrayList() constructs an empty list with an initial capacity of ten. Each ArrayList instance has a capacity. The capacity is the size of the array used to store the elements in the list. It is always at least as large as the list size. As elements are added to an ArrayList, its capacity grows automatically. The details of the growth policy are not specified beyond the fact that adding an element has constant amortized time cost. An application can increase the capacity of an ArrayList instance before adding a large number of elements using the ensureCapacity operation. This may reduce the amount of incremental reallocation. »
Voici ce que dit la Javadoc au sujet de FileWriter : « Convenience class for writing character files. The constructors of this class assume that the default character encoding and the default byte-buffer size are acceptable. To specify these values yourself, construct an OutputStreamWriter on a FileOutputStream. Whether or not a file is available or may be created depends upon the underlying platform. Some platforms, in particular, allow a file to be opened for writing by only one FileWriter (or other file-writing object) at a time. In such situations the constructors in this class will fail if the file involved is already open. FileWriter is meant for writing streams of characters. For writing streams of raw bytes, consider using a FileOutputStream. »
Voici ce que dit la Javadoc au sujet de BufferedWriter : « Writes text to a character-output stream, buffering characters so as to provide for the efficient writing of single characters, arrays, and strings. The buffer size may be specified, or the default size may be accepted. The default is large enough for most purposes. A newLine() method is provided, which uses the platform's own notion of line separator as defined by the system property line.separator. Not all platforms use the newline character ('
') to terminate lines. Calling this method to terminate each output line is therefore preferred to writing a newline character directly. In general, a Writer sends its output immediately to the underlying character or byte stream. Unless prompt output is required, it is advisable to wrap a BufferedWriter around any Writer whose write() operations may be costly, such as FileWriters and OutputStreamWriters. [..] Without buffering, each invocation of a print() method would cause characters to be converted into bytes that would then be written immediately to the file, which can be very inefficient. »
16-F. Quelques liens▲
Une bonne présentation de JUnit 4 : https://rpouiller.developpez.com/tutoriels/java/tests-unitaires-junit4
La RFC 4180 présentant le format CSV : http://tools.ietf.org/html/rfc4180RFC 4180
Éditeur online YUML pour faire des diagrammes UML sympas : http://www.yuml.meYUML.ME
Une bonne présentation des Regex : https://cyberzoide.developpez.com/java/regex/Les regex sur developpez.com
Une bonne présentation des Google-Collections : https://thierry-leriche-dessirier.developpez.com/tutoriels/java/tuto-google-collections/Les Google-Collections sur developpez.com
16-G. List ou Set ?▲
Dans le programme, « chapitre VI-A - Choix », je déclare la liste des séparateurs acceptables en tant que List et non en tant que Set. Ce choix peut sembler étrange dans la mesure où il est évident qu'il ne doit pas y avoir de doublon dans cette liste. Par contre, l'ordre des items de la liste aura son importance dans le cadre de la recherche du bon séparateur, d'où le choix d'une List et non d'un Set.
public final static Set<Character> AVAILABLE_SEPARATORS_AS_SET = Collections.unmodifiableSet(new LinkedHashSet<Character>(
Arrays.asList(',', ';', '\t', '|')));Les interfaces List et Set font partie de l'API Java-Collections. Une List (ex. ArrayList) est tout simplement une liste dans laquelle les éléments sont ordonnés. Une Set est également une sorte de liste, mais dans laquelle les items ne sont pas ordonnés. En outre un élément ne peut pas être présent deux fois dans un Set.